Building a Search GPT with Dynamiq

.webp)
The following article explores how to create a search-driven application, "Search GPT," using Dynamiq’s library. We'll demonstrate three different backend architectures to process and respond to user queries in real time, leveraging both programmatic and visual approaches to configure Dynamiq workflows. The article also includes a Streamlit-based frontend, providing a user-friendly interface for testing and refining our search tool.
.gif)
Project Overview and Goal
This project aims to create a Search GPT application using Dynamiq to power a flexible, intelligent search backend. By using Dynamiq's workflows, agents, and tools, we can design three distinct backends that showcase Dynamiq's capabilities to process queries and generate accurate search results in various ways:
- Approach 1: Building a straightforward workflow using the Dynamiq UI, deployed as an API endpoint for search processing.
- Approach 2: Implementing the workflow using Dynamiq's code library to manually set up nodes and tools.
The goal is to demonstrate how each approach offers unique strengths for different needs, from simplicity and ease of deployment to highly customizable logic.
Project Structure and Files
File Overview
- README.md: Project documentation.
- app.py: Streamlit app frontend, handling query input and displaying search results.
- run.sh: Script to launch the application.
- server.py: Server logic for Approach 2, defining nodes, agents, and workflow in code.
- server_via_dynamiq.py: API-based server for Approach 1, connecting to Dynamiq UI-generated endpoint.
Directory Structure
Approach 1: Dynamiq UI-Based Pipeline
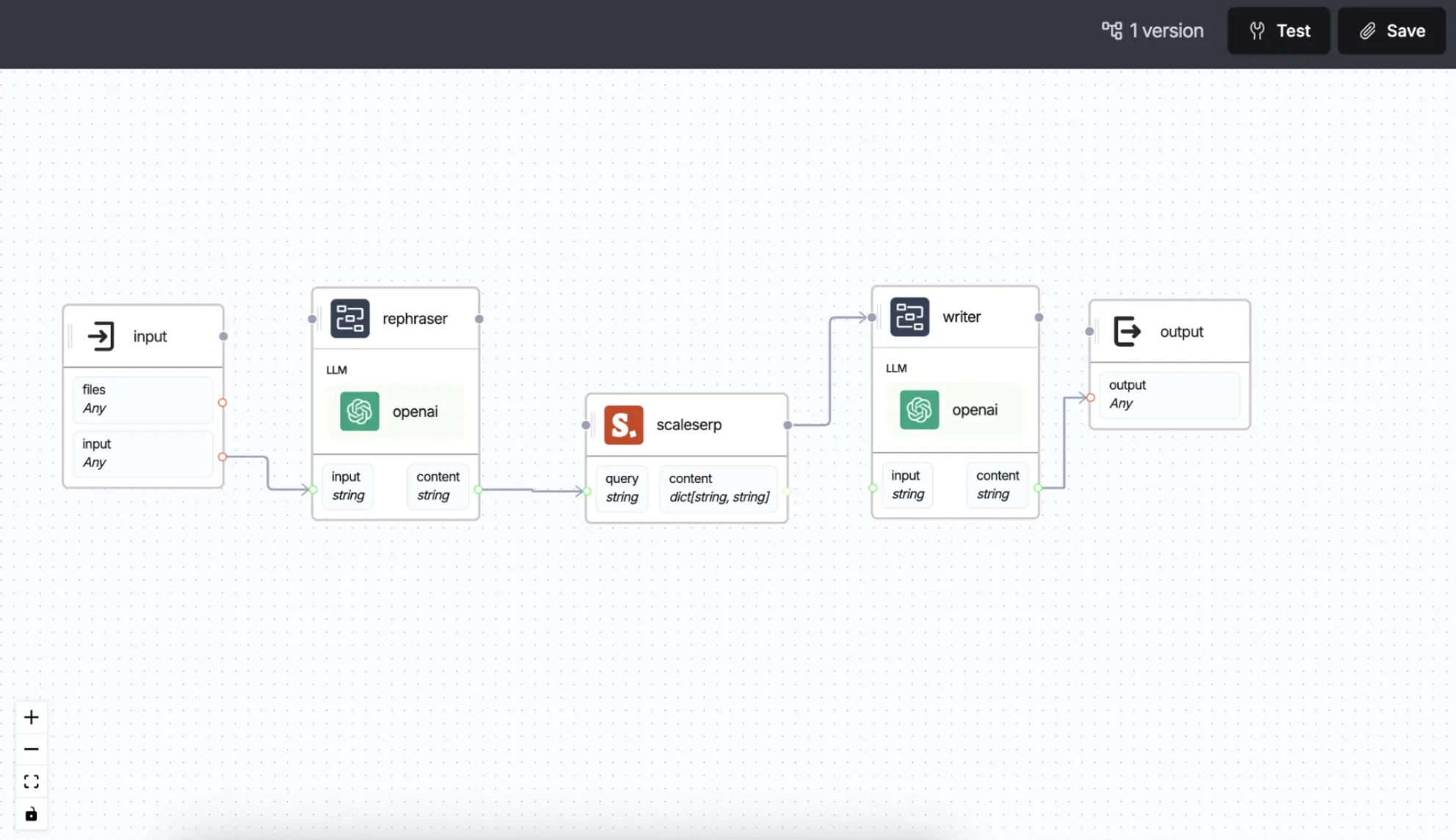
To set up a simple and efficient search workflow that processes user queries by rephrasing, retrieving relevant information, and synthesizing a well-structured response. The workflow involves:
Rephrasing the input query.
- Searching for relevant information.
- Synthesizing the response.
- Displaying the final output to the user.
Components Overview
The workflow uses the following components, as seen in the images:
- Input Node: Captures the user’s original query.
- Rephraser Agent: Rephrases the query to make it search-friendly.
- Search Tool (ScaleSerp): Queries the web to retrieve information based on the rephrased input.
- Writer Agent: Synthesizes a clear and structured response from the search results.
- Output Node: Outputs the final answer back to the user.
Each component is represented as a node in the Dynamiq UI, with connections between them defining the data flow from input to output.
Step 1: Set Up the Input Node
- Purpose: This node serves as the entry point for user queries. It receives the raw input, such as "Tell me about the current status of the Apple stock."
- Configuration:some text
- Field: input (of type string for query text)
- Placeholder: "User query here"
- Connection: The input node is connected directly to the Rephraser Agent to pass the query for rephrasing.
Step 2: Configure the Rephraser Agent
- Purpose: The Rephraser Agent uses a language model (e.g., OpenAI’s GPT) to refine the query. It simplifies and clarifies the query, making it more effective for a search tool.
- Configuration:some text
- Connect to a pre-trained language model, like OpenAI, to perform rephrasing.
- Input Field: input (query text)
- Output Field: content (rephrased query text)
- Example Function: If the input is “Tell me about the current status of the Apple stock,” the rephrased output might be “Current Apple stock status.”
Connection: The rephrased query is passed to the Search Tool node.
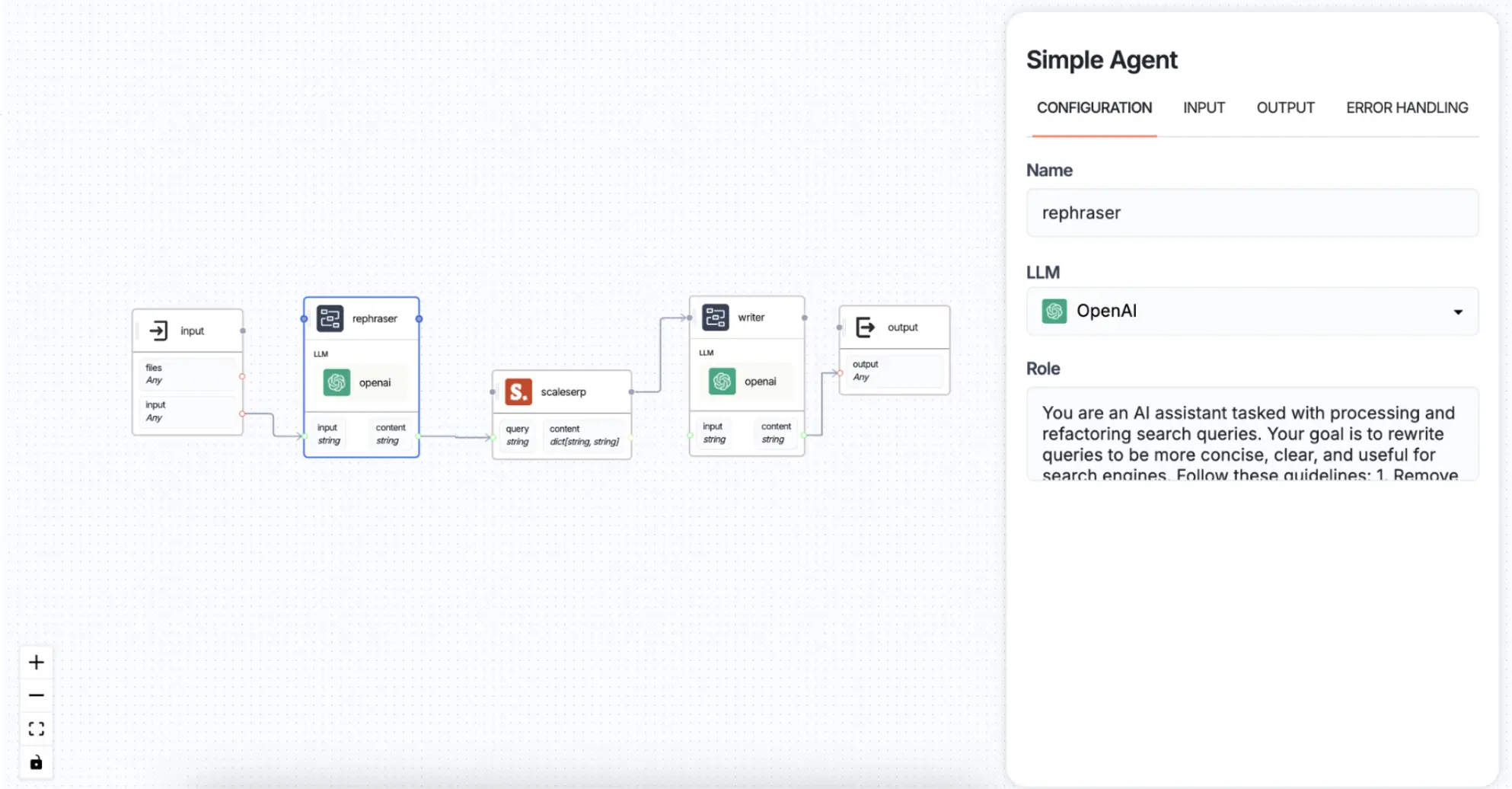
Step 3: Integrate the Search Tool (ScaleSerp)
- Purpose: This tool is responsible for retrieving relevant data based on the refined query. It connects to an external API (like ScaleSerp) to search for information online.
- Configuration:some text
- Input Field: query (accepts the rephrased query)
- Output Field: content (retrieves a structured dictionary with search results)
- Configure with API key and endpoint for ScaleSerp or a similar search tool.
- Example Output: The search tool returns structured data, such as relevant articles, summaries, and market data about Apple stocks.
- Connection: The search results are sent to the Writer Agent for synthesis.
.webp)
.webp)
Step 4: Implement the Writer Agent
- Purpose: The Writer Agent synthesizes the information retrieved from the search tool, creating a coherent response that addresses the user’s query.
- Configuration:some text
- Connect to a language model (e.g., OpenAI) for content synthesis.
- Input Field: input (search results)
- Output Field: content (final synthesized answer)
Example Function: If the search results contain stock data, the Writer Agent may generate a paragraph like:
- Connection: The synthesized response is routed to the Output Node.
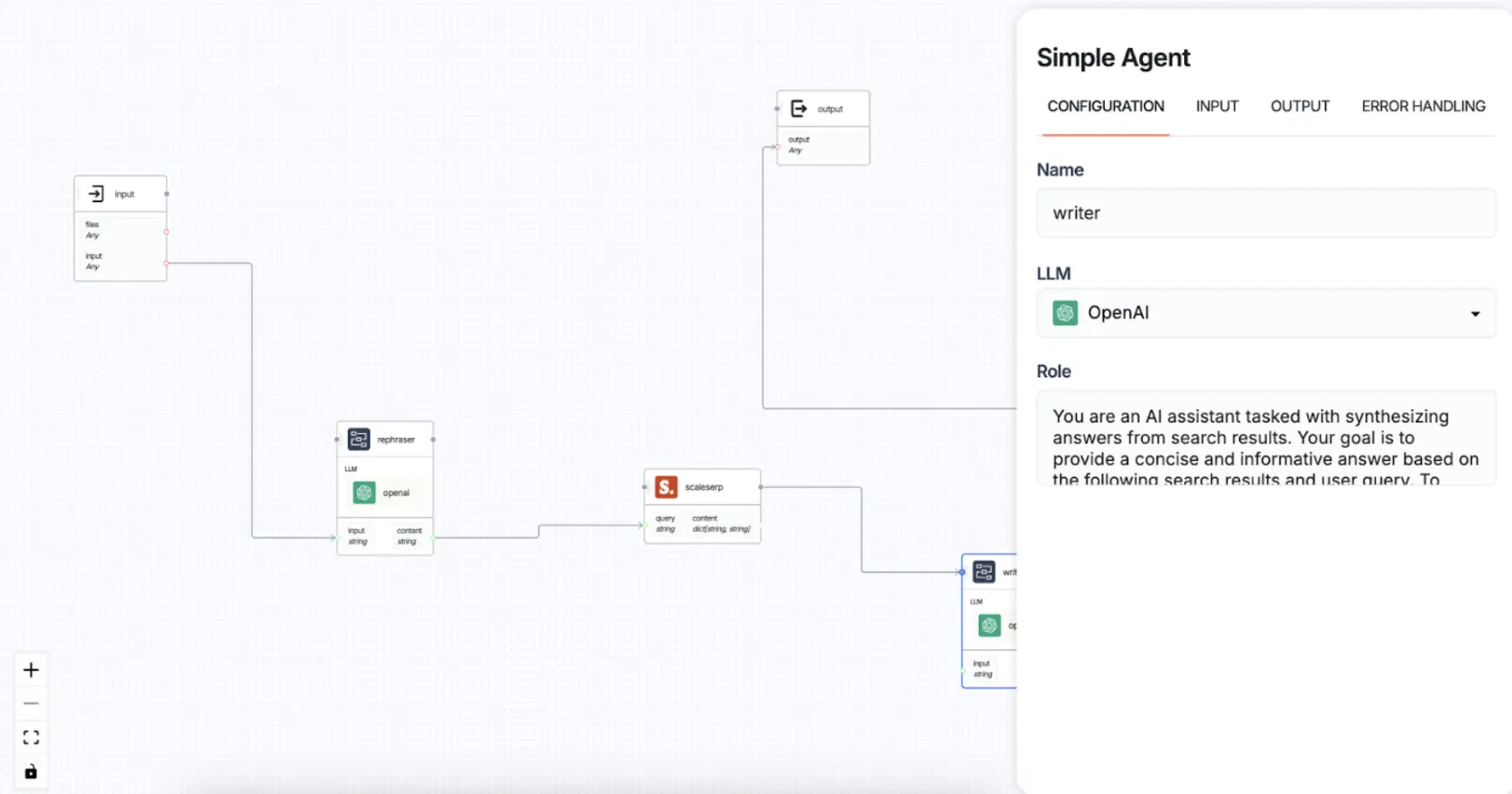
Step 5: Set Up the Output Node
- Purpose: The Output Node captures and displays the final answer back to the user.
- Configuration:some text
- Field: output (structured answer as a string)
Example Output: The final response might look like:
Run and Evaluate the Workflow
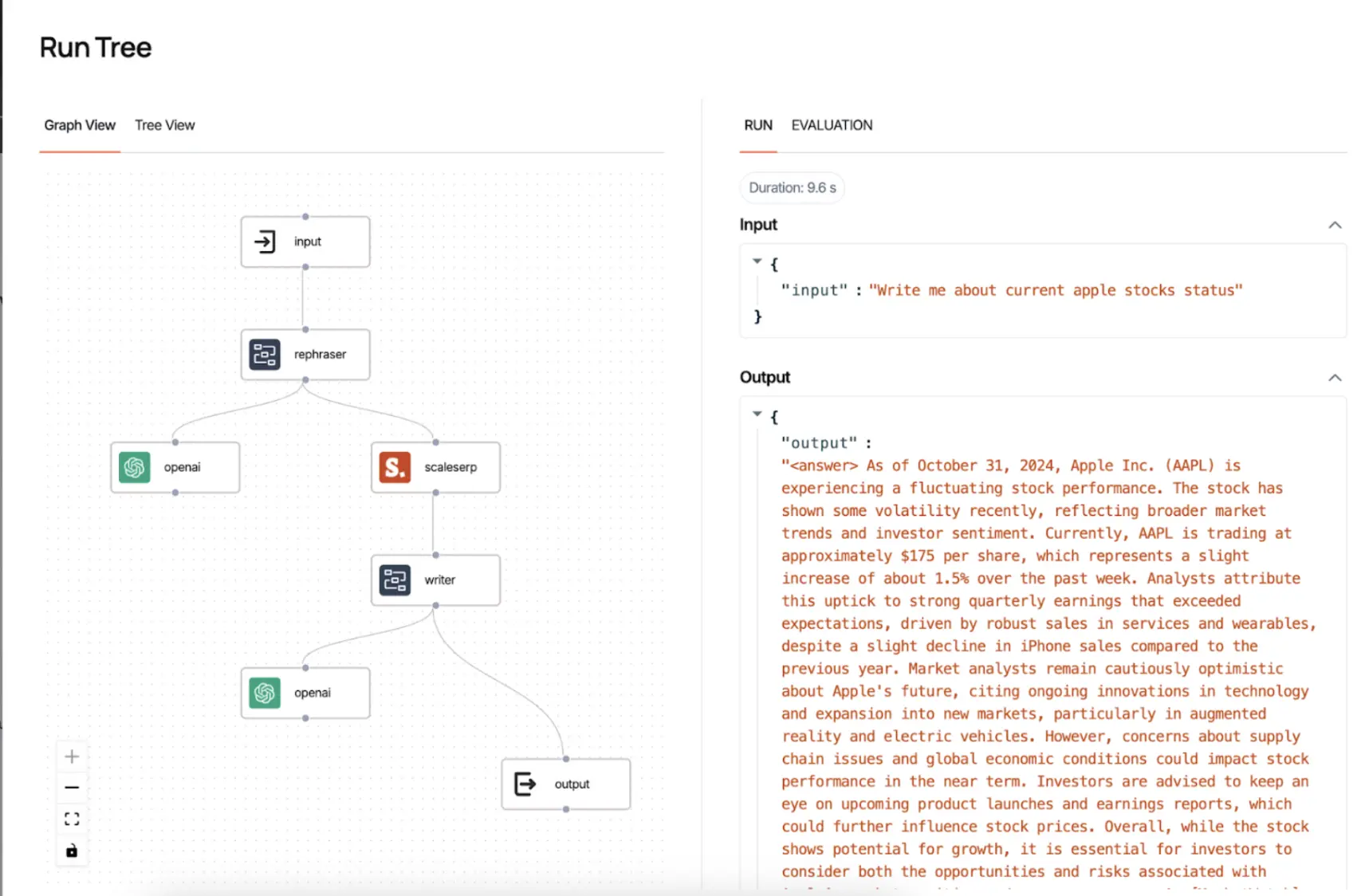
- Testing: Input a sample query such as “Write me about current Apple stock status” in the interface.
- Execution:some text
- The query passes through each node sequentially, from rephrasing to search, synthesis, and output.
- The execution trace can be viewed in Dynamiq’s Run Tree (as shown in the second image), where the input and output of each node are displayed.
- Evaluation:some text
- Duration: The total processing time for the workflow (e.g., 9.6 seconds).
- Results: The final output is displayed in a structured format, including the rephrased query and a synthesized, well-researched answer about Apple’s stock status.
Deploying and Accessing the Workflow via API
Once we've tested and verified that our pipeline functions effectively, we’re ready to deploy it as an accessible service. This allows external applications to utilize the workflow through an API, enabling dynamic query processing in real-time.
By deploying the workflow as an API, our setup can be integrated with any frontend, such as a Streamlit app, to give users real-time access to structured responses for their queries. Below is a simple demonstration of how this is done, complete with code snippets that show API handling and response streaming for the frontend.
Implementing the Workflow as an API: Key Steps
Step 1: Prepare the API Configuration
First, we need to configure our endpoint and authorization. These are handled securely through environment variables to protect sensitive information such as API keys.
Step 2: Sending Queries and Processing Results
The function below, process_query, submits user queries to the deployed Dynamiq API workflow. It sends the query to the backend pipeline, processes it, and streams results back in real-time to improve user experience.
- Query Submission: The process_query function takes a user query, formats it as JSON, and sends it to Dynamiq’s endpoint.
- Content Extraction: Once the response is received, specific tags <sources> and <answer> are parsed. This separates sources from the answer text.
- Streaming Output: The function yields pieces of information gradually. It starts by streaming the sources, then the answer in small chunks to simulate real-time data flow.
This deployed API can serve as the foundation for applications needing structured and immediate responses to user queries, enhancing interactivity and delivering a high-quality user experience.Approach 2: Programmatic Workflow with Dynamiq CodeIn this approach, we programmatically set up a workflow using the Dynamiq library. The workflow includes agents that rephrase queries, retrieve information, and synthesize comprehensive answers with source citations. This method provides fine-grained control over each component and allows for custom logic within each step.Below is a detailed, step-by-step explanation of each part of the code and how it constructs the search pipeline.
Initial Step: Import library and modules
Step 1: Setting Up Utility Functions and Roles
1. Utility Function: extract_tag_content
- This helper function extracts content wrapped within specific XML-like tags from a given text.
- For example, if the text contains <answer>Some answer here</answer>, calling extract_tag_content(text, "answer") will return "Some answer here".
2. Agent Roles: AGENT_QUERY_ROLE and AGENT_ANSWER_ROLE
- AGENT_QUERY_ROLE: This role guides the rephraser agent to refine queries, removing unnecessary words and focusing on keywords.
- AGENT_ANSWER_ROLE: This role is for the answer synthesizer agent, instructing it to compile a well-structured, cited answer based on search results.
Step 2: Setting Up Language Models
1. Setup Language Models (setup_llm):
- Two language models (llm_mini and llm) are initialized for different tasks. The llm_mini model, with a smaller max token limit, is used for query rephrasing, while llm is used for generating more detailed answers.
- These models are configured for specific providers (e.g., GPT) with different parameters for control over token usage and output length.
Step 3: Defining Agents and Tools
1. Agent: Query Rephraser (agent_query_rephraser)
- This agent rephrases the user’s query according to the rules defined in AGENT_QUERY_ROLE. It uses llm_mini to create concise, search-optimized versions of the input query.
2. Tool: Search Tool (search_tool)
- The ScaleSerpTool interacts with an external search engine API (ScaleSerp) to retrieve information based on the rephrased query.
- search_tool is configured with a location parameter, and it depends on the output from agent_query_rephraser.
- The input_transformer is set up to pass only the rephrased query to the search tool, using a selector.
3. Agent: Answer Synthesizer (agent_answer_synthesizer)
- This agent synthesizes an answer using the search results from search_tool and the rephrased query from agent_query_rephraser.
- agent_answer_synthesizer is configured with AGENT_ANSWER_ROLE to generate a structured answer with citations.
- The input_transformer uses selectors to pass both the rephrased query and search results to this agent.
Step 4: Creating and Running the Workflow
1. Setting Up Workflow and Tracing
- A Workflow is created using a Flow that includes the query rephraser, search tool, and answer synthesizer agents.
2. Processing User Queries (process_query function)
- This function runs the workflow with a user query, processes the result, and yields chunks of the answer in real time.
- The final answer and sources are extracted using extract_tag_content, streaming the sources first and then the answer.
Streamlit Frontend Integration and Demo
The Streamlit frontend code is designed to create a responsive, interactive interface for the search application powered by Dynamiq. The logic flows through a series of functions to handle the user input, display query results in real time, and manage the session state. Let’s walk through the main logical components of the code to understand how they work together.
1. Session State Management
Streamlit runs scripts from top to bottom each time the user interacts with the app (e.g., clicks a button or submits a form). To maintain persistent data (like query history and intermediate states), we use Streamlit's session state. This is handled with two functions:
initialize_session_state()
This function ensures that essential session state variables (query_history, current_query, and clear_input) are initialized only once. If these variables are not yet present in st.session_state, it sets them with initial values.
- Purpose: Avoids reinitializing state variables on each run, preserving values across interactions.
- Logic: Checks if each key exists in st.session_state; if not, it sets a default value.
reset_conversation()
This function resets the session state to start a new conversation. It clears the query_history, current_query, and clear_input fields, effectively wiping the session for a fresh start.
- Purpose: Provides a clean slate for a new query session.
- Logic: Resets all key session variables to their default values.
2. Handling Query Submission
The handle_query_submission() function is at the core of the app’s logic. It processes user input and displays the search result incrementally, simulating a streaming experience. This is done by receiving query chunks from the backend and updating the display in real time.
- Logic Flow:
- Empty Check: Ensures the query isn’t empty. If it is, a warning is displayed.
- Query History: Adds the query to query_history for record-keeping, allowing users to see past queries in the same session.
- Result Display:
- A placeholder (result_placeholder) is created to display the result text, which will be incrementally updated.
- The app displays a spinner while waiting for the backend to process the query.
- Streaming Effect:
- process_query(query) yields chunks of data (from the backend workflow).
- Each chunk is appended to result_text, and result_placeholder.write() updates the display in real time.
- A brief delay (time.sleep(0.05)) simulates the experience of streaming results.
- Clear Input Flag: After the query is processed, clear_input is set to True to reset the input field for the next query.
3. Main Function: main()
The main() function defines the layout and interactions of the Streamlit app. It includes a title, an input field for queries, and buttons for submitting queries or starting a new query session.
- Layout:
- Title: Displays a title for the app ("Search Application").
- Query Input: A text input box (st.text_input) allows the user to enter a search query.
- Submit Button: The "Submit" button triggers handle_query_submission() when clicked, processing the query.
- Start New Query Button: The "Start New Query" button triggers reset_conversation() to clear the session. st.experimental_rerun() is used to refresh the app, effectively clearing all input fields and previous results.
- Logic for Clearing Input:
- clear_input flag is checked after each submission to reset the input field for the next query.
Conclusion
In this article, we've explored the creation of a search-driven application, "Search GPT," powered by Dynamiq. Through two unique approaches - API-driven and programmatic - we've demonstrated how Dynamiq’s capabilities can be leveraged to build intelligent, adaptable search backends that efficiently respond to complex user queries.
The UI-based approach offers a rapid deployment path with easy-to-configure workflows that handle rephrasing, searching, and synthesizing responses via Dynamiq’s visual interface. This method is ideal for applications requiring quick deployment and straightforward query processing. On the other hand, the programmatic approach, built directly using Dynamiq’ code library, provides extensive customization options and fine-grained control over each component of the search pipeline. This flexibility is particularly valuable in applications with unique or evolving requirements, allowing developers to tailor logic and integrations precisely to their needs.
The integration of a Streamlit-based frontend enhances the user experience, providing an interactive interface where users can enter queries, view real-time responses, and explore search results incrementally. The streaming effect simulates real-time data processing, making it highly engaging and responsive for end-users.
Together, these approaches showcase how Dynamiq empowers developers to design scalable, intelligent search applications that can serve diverse user needs. Whether you're looking to deploy a simple search engine or a highly customized query-processing backend, Dynamiq's flexibility and power offer a robust foundation for building applications that respond to user input with precision and speed.
By leveraging Dynamiq’s workflows, agents, and tools, developers can create efficient, adaptable search-driven applications that stand out in delivering fast, accurate, and user-friendly results.


